Hadoop Node Tries to Add Users Again on Its Own
Twitter runs multiple large Hadoop clusters that are amongst the biggest in the world. Hadoop is at the cadre of our data platform and provides vast storage for analytics of user actions on Twitter. In this mail, we will highlight our contributions to ViewFs, the client-side Hadoop filesystem view, and its versatile usage here.
ViewFs makes the interaction with our HDFS infrastructure as uncomplicated equally a single namespace spanning all datacenters and clusters. HDFS Federation helps with scaling the filesystem to our needs for number of files and directories while NameNode High Availability helps with reliability within a namespace. These features combined add pregnant complexity to managing and using our several large Hadoop clusters with varying versions. ViewFs removes the need for us to call back complicated URLs past using simple paths. Configuring ViewFs itself is a complex task at our scale. Thus, nosotros run TwitterViewFs, a ViewFs extension we adult, that dynamically generates a new configuration so we take a simple holistic filesystem view.
Hadoop at Twitter: scalability and interoperability
Our Hadoop filesystems host over 300PB of data on tens of thousands of servers. We calibration HDFS past federating multiple namespaces. This arroyo allows the states to sustain a high HDFS object count (inodes and blocks) without resorting to a single big Coffee heap size that would endure from long GC pauses and the disability to use compressed oops. While this arroyo is great for scaling, it is non piece of cake for usa to use because each member namespace in the federation has its own URI. We use ViewFs to provide an illusion of a single namespace within a single cluster. As seen in Figure 1, under the chief logical URI we create a ViewFs mount table with links to the appropriate mount bespeak namespaces for paths beginning with /user, /tmp, and /logs, correspondingly.
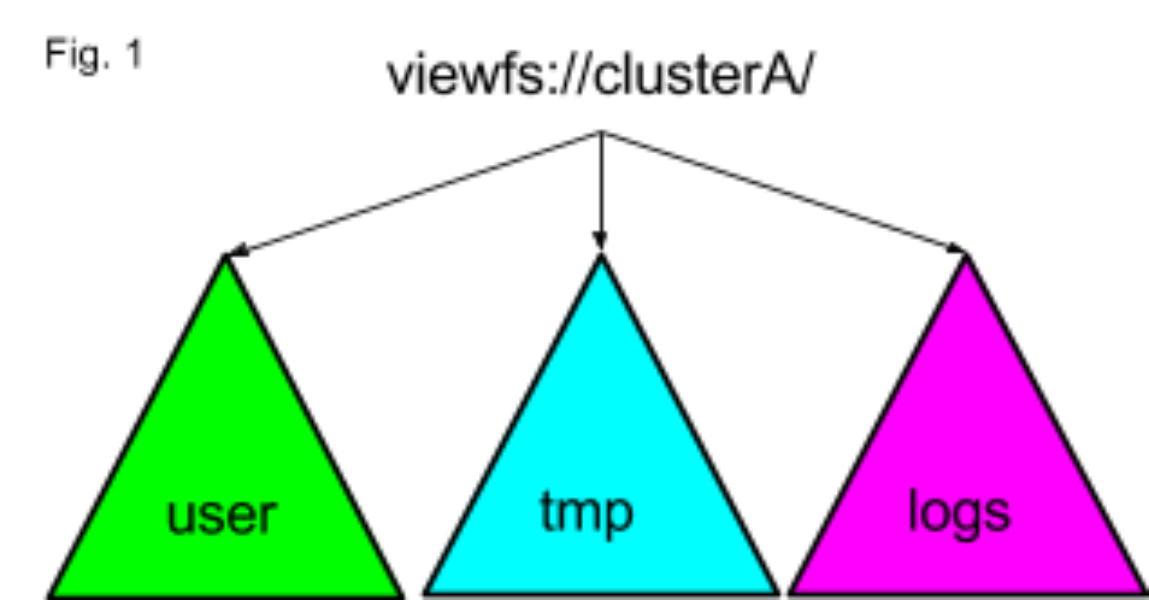
The configuration of the view depicted in Figure i translates to a lengthy configuration of a mount table named clusterA. Logically, you tin think of this every bit a set of symbolic links. We abridge such links simply as /logs->hdfs://logNameSpace/logs. Here y'all can detect more details nearly our TwitterViewFs extension to ViewFs that handles both hdfs:// and viewfs:// URI's on the client side to onboard hundreds of Hadoop 1 applications without code changes.
Twitter's Hadoop client and server nodes store configurations of all clusters. At Twitter, we don't invoke the hadoop command straight. Instead we use a multiversion wrapper hadoop that dispatches to dissimilar hadoop installs based on a mapping from the configuration directory to the advisable version. We store the configuration of cluster C in the datacenter DC abbreviated every bit C@DC in a local directory /etc/hadoop/hadoop-conf-C-DC, and we symlink the main configuration directory for the given node as /etc/hadoop/conf.
Consider a DistCp from source to destination. Given a Hadoop two destination cluster (which is very common during migration), the source cluster has to be referenced via read-simply Hftp regardless of the version of the source cluster. In example of a Hadoop 1 source, Hftp is used because the Hadoop 1 client is not wire-uniform with Hadoop 2. In case of a Hadoop 2 source, Hftp is used as there is no single HDFS URI because of federation. Moreover, with DistCp nosotros take to apply the destination cluster configuration to submit the task. Nevertheless, the destination configuration does non contain information about HA and federation on the source side. Our previous solution implementing a serial of redirects to the correct NameNode is bereft to cover all scenarios encountered in production so we merge all cluster configurations on the customer side to generate i valid configuration for HDFS HA and ViewFs for all Twitter datacenters as described in the next department.
User-friendly paths instead of long URIs
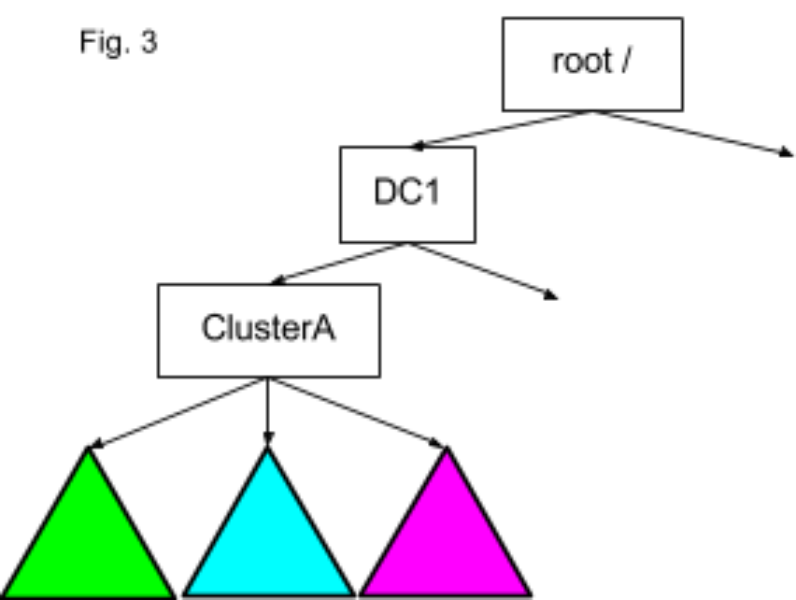
We developed user-friendly paths instead of long URIs and enabled native admission to HDFS. This removes the overwhelming number of different URIs and greatly increases the availability of the data. When nosotros employ multi-cluster applications, we take to cope with the full URIs that sometimes have a long authority part represented by a NameNode CNAME. Furthermore, if the cluster mix includes both Hadoop ane and Hadoop 2, which are not wire-uniform, we unfortunately accept to remember which cluster to address via the interoperable Hftp filesystem URI. The volume of questions around this area on our internal Twitter employee mailing lists, chat channels and office hours motivated the states to solve this URI problem for good on the Hadoop two side. We realized that since we already present multiple namespaces equally a single view within a cluster, we should do the same across all all clusters within a datacenter, or even beyond all datacenters. The thought is that a path /path/file at the cluster C1 in the datacenter DC1 should be mounted past the ViewFs in each cluster as /DC1/C1/path/file as shown Figure three. This manner we will never accept to specify a full URI, nor remember whether Hftp is needed because we tin can transparently link via Hftp within ViewFs.
With our growing number of clusters and number of namespaces per cluster, it would be very cumbersome if we had to maintain additional mountain table entries in each cluster configuration manually equally information technology turns into a O(n2) configuration problem. In other words, if nosotros modify the configuration of just i cluster we demand to bear on all n cluster configurations just for ViewFs. Nosotros also need to handle the HDFS client configuration for nameservices because otherwise mount point URIs cannot exist resolved by the DFSClient.
It's quite common that we have the same logical cluster in multiple datacenters for load balancing and availability: C1@DC1, C1@DC2, etc. Thus, nosotros decided to add together some more features to TwitterViewFs. Instead of populating the configurations administratively, our lawmaking adds the configuration keys needed for the global cross-datacenter view at the runtime during the filesystem initialization automatically. This allows us to change existing namespaces in i cluster, or add together more than clusters without touching the configuration of the other clusters. By default our filesystem scans the glob file:/etc/hadoop/hadoop-conf-*.
The following steps construct the TwitterViewFs namespace. When the Hadoop client is started with a specific C-DC cluster configuration directory, the following keys are added from all other C'-DC' directories during the TwitterViewFs initialization:
- If at that place is a ViewFs mount point link like /path->hdfs://nameservice/path in C'-DC', so nosotros will add a link /DC'/C'/path->hdfs://nameservice/path. For the Effigy one example higher up, we would add to all cluster configurations:/dc/a/user=hdfs://dc-A-user-ns/user
- Similarly, for consistency, we duplicate all conventional links /path->hdfs://nameservice/path for C-DC as /DC/C/path->hdfs://nameservice/path. This allows the states to use the same notation regardless of whether we work with the default C-DC cluster or a remote cluster.
- We can easily detect whether the configuration C'-DC' that we are about to merge dynamically is a legacy Hadoop ane cluster. For Hadoop 1, the primal fs.defaultFS points to an hdfs:// URI, whereas for Hadoop ii, it points to a viewfs:// URI. Our Hadoop 1 clusters consist of a single namespace/NameNode, so nosotros tin can transparently substitute the hftp scheme for the hdfs scheme and simply add the link: /DC/C'/->hftp://hadoop1nn/
Now the TwitterViewFs namespace is defined. Notwithstanding, at this phase ViewFs links pointing to hdfs nameservices cannot be used past the DFSClient withal. In guild to make HA nameservice URIs resolvable, we need to merge the relevant HDFS customer configuration from all hdfs-site.xml files in C'-DC' directories. Here's how we practice this:
- HDFS uses the cardinal dfs.nameservices to shop a comma-separated list of all the nameservices DFSClient needs to resolve. We append the values of all C'-DC' to the dfs.nameservices value of the electric current cluster. We typically have 3-4 namespaces per cluster.
- All namespace-specific parameters in HDFS conduct the namespace somewhere in the suffix. Twitter namespace names are unique and mnemonic enough that a simple heuristic of copying all key-value pairs from C'-DC' where the key proper noun begins with "dfs" and contains one of the nameservices from Footstep 1 is sufficient.
Now we have a working TwitterViewFs with all clusters accessible via the /DC/C/path convention regardless of whether a specific C is a Hadoop ane or a Hadoop ii cluster. A powerful instance of this scheme is to check the quota of domicile directories on all clusters in one single command: hadoop fs -count '/{dc1,dc2}/*/user/gera'
Nosotros tin can also easily run fsck on any of the namespaces without remembering the exact complex URI: hadoop fsck /dc1/c1/user/gera
Nosotros want a consistent experience when working with the local filesystem and HDFS. It is much easier to remember conventional commands such equally cp than "syntactic-sugar commands" such as copyFrom/ToLocal, put, get, etc. A regular hadoop cp control requires a full file:/// URI and that is what the syntactic sugar commands attempt to simplify. When mounted with ViewFs even this is non necessary. Similar to how nosotros add ViewFs links for the cluster /DC/cluster, we add ViewFS links to the TwitterViewFs configuration such equally:
/local/user/<user>->file:/home/<user>
/local/tmp->file:/${hadoop.tmp.dir}
Then, copying a file from a cluster to a local directory looks similar:
hadoop fs -cp /user/laurent/debug.log /local/user/laurent/
The simple, unified cantankerous-DC view on an otherwise fragmented Hadoop namespace has pleased internal users and sparked public involvement.
High availability for multi-datacenter environment
Beyond this, nosotros created a project lawmaking-named Nfly (Due north every bit in North datacenters), where we implement much of the HA and multi-dc functionality in ViewFs itself in gild to avert unnecessary code duplication. Nfly is able to link a unmarried ViewFs path to multiple clusters. When using Nfly one appears to interact with a unmarried filesystem while in reality in the background each write is applied to all linked clusters and a read is performed from either the closest cluster (according to NetworkTopology) or the one with the almost recent available re-create. Nfly makes cross-datacenter HA very easy. Fusion of multiple physical paths to 1 logical more bachelor path is achieved with a new replication multi-URI Inode. This is tailored to a mutual HDFS usage pattern in our highly available Twitter services. Our services host their data on some logical cluster C. New service data versions are created periodically to relatively infrequently and read by many different servers. There is a corresponding HDFS cluster in multiple datacenters. When the service runs in datacenter DC1 it prefers to read from /DC1/C for lower latency. However, when data under /DC1/C is unavailable the service wants to failover its reads to the higher latency path /DC2/C instead of exposing the outage to its users.
A conventional ViewFs mount directly inode points to a single URI via ChRootedFileSystem, every bit you can see at that place is i arrow between nodes in Figure 3 to a higher place. The user namespace (which is green above) of ClusterA in datacenter DC1 is mounted using the mount point entry /DC1/clusterA/user->hdfs://dc1-A-user/user. When the application passes the path /DC1/clusterA/user/lohit information technology will be resolved every bit follows. The root portion of the path marked bold between the root / and the mount point inode user (elevation of the namespace tree inFigure three) is replaced by the link target value hdfs://dc1-A-user/user. Then the result hdfs://dc1-A-user/user/lohit is used to admission the concrete FileSystem. Replacing of root portion is called chrooting in this context, hence the name ChRootedFileSystem. Thus, if we had multiple URI's in the inode, nosotros could back a single logical path by multiple physical filesystems typically residing in different datacenters.
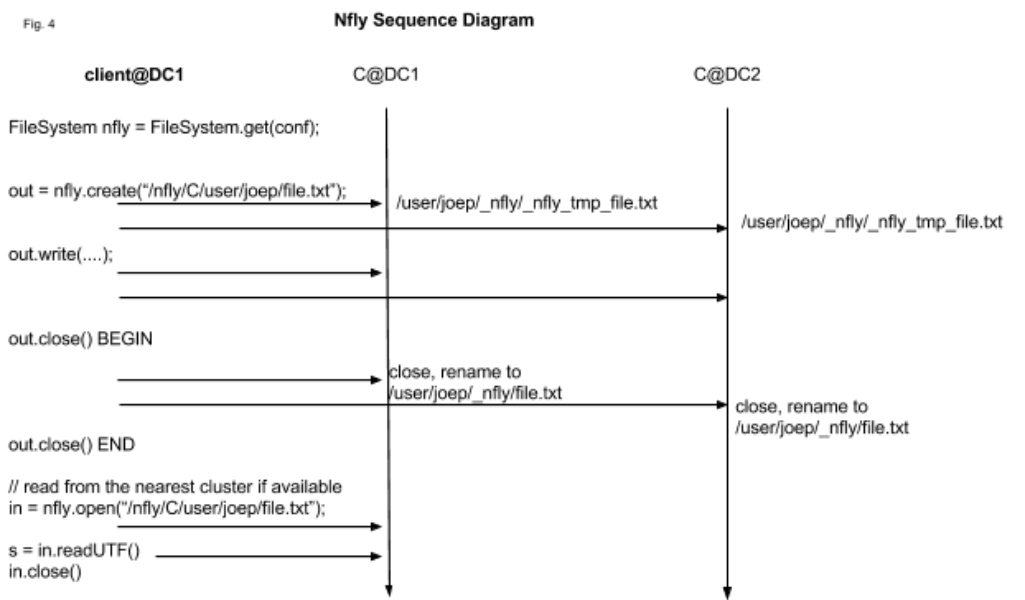
Consequently, we introduce a new blazon of link pointing to a listing of URIs each wrapped in a ChRootedFileSystem. The basic principle that a write call is propagated to each filesystem represented past the URIs synchronously. On the read path, the FileSystem client picks the URI pointing to the closest destination, such as in the aforementioned datacenter. A typical usage is/nfly/C/user->/DC1/C/user,/DC2/C/user,… The message sequence diagram in Effigy 4 illustrates this scenario.
This drove of ChRootedFileSystem instances is fronted by the Nfly filesystem object that is used for the mount betoken inode. The Nfly filesystem backs a unmarried logical path /nfly/C/user/<user>/path by multiple physical paths. Information technology supports setting minReplication. As long as the number of URIs on which an update has succeeded is greater than or equal to minReplication, exceptions are merely logged but not thrown. Each update functioning is currently executed serially. All the same, we do plan to add a feature to employ parallel writes from the client as far equally its bandwidth permits.
With Nfly a file create or write is executed as follows:
- Creates a temporary invisible _nfly_tmp_file in the intended chrooted filesystem.
- Returns a FSDataOutputStream that wraps output streams returned by A.
- All writes are forwarded to each output stream.
- On close of stream created in B, all n streams are closed, and the files are renamed from _nfly_tmp_file to file. All files receive the same mtime corresponding to the client organisation time equally of beginning of this step.
- If at least minReplication destinations have gone through steps 1 to 5 without failures the filesystem considers the transaction logically committed; Otherwise it tries to clean upwards the temporary files in a best-effort try.
As for reads, nosotros support a notion of locality similar to HDFS /DC/rack/node. We sort URIs using NetworkTopology by their authorities. These are typically host names in simple HDFS URIs. If the authorization is missing as is the example with the local file:/// the local host proper noun is causeless InetAddress.getLocalHost(). This ensures that the local file system is ever considered to be the closest 1 to the reader. For our Hadoop 2 hdfs URIs that are based on nameservice ids instead of hostnames it is very easy to adjust the topology script since our nameservice ids already contain the datacenter reference. Every bit for rack and node nosotros can simply output any string such equally /DC/rack-nsid/node-nsid, because nosotros are concerned with but datacenter-locality for such filesystem clients.
There are two policies/additions to the read phone call path that go far more computationally expensive, only improve user feel:
- readMostRecent - Nfly first checks mtime for the path under all URIs and sorts them from about to least contempo. Nfly then sorts the set of URIs with the most contempo mtime topologically in the aforementioned way as described in a higher place.
- repairOnRead - Nfly already has to contact all underlying destinations. With repairOnRead, the Nfly filesystem would additionally attempt to refresh destinations with the path missing or a stale version of the path using the nearest available most contempo destination.
As we pointed out before, managing ViewFs configurations can already be quite cumbersome, and Nfly mounts make it even more complicated. Luckily, TwitterViewFs provides mechanisms with sufficient flexibility to add more than lawmaking in gild to generate useful Nfly configurations "on the fly". If a Twitter employee wants their dwelling house directories on the logical cluster C across all DC's nflied under /nfly/C/user/<user>, she simply specifies -Dfs.nfly.mountain=C. If she then additionally wants to enshroud the files locally nether /local/user/<user>/C, she specifies -Dfs.nfly.local=true.
Future work
The multi-URI inode introduced for Nfly lays the groundwork for the read-only Merge FileSystem that transparently merges inodes from the underlying filesystems. This is something we're currently working on implementing. It will allow us to cut the number of mount table entries dramatically in comparison to unmarried-URI inode approach. The target use example for the Merge FileSystem is to split an existing namespace, for example the user namespace, into two namespaces without the demand for users to arrange code, and without bloating configuration. To see this illustrated, you tin can compare Figures v and six.


In this post we shared our approach to managing Hadoop filesystems at Twitter: scaling to run into our needs for vast storage using federated namespaces while maintaining simplicity through ViewFs. We extended ViewFs to simplify its operation in face of always growing number of clusters and namespaces in multiple datacenters and added Nfly for cross-datacenter availability of HDFS data. We believe that the broader Hadoop user customs will benefit from our experience.
Acknowledgements
We would like to thank Laurent Goujon, Lohit VijayaRenu, Siqi Li, Joep Rottinghuis, the Hadoop squad at Twitter and the wider Hadoop community for helping the states scale Hadoop at Twitter.
Source: https://blog.twitter.com/engineering/en_us/a/2015/hadoop-filesystem-at-twitter
0 Response to "Hadoop Node Tries to Add Users Again on Its Own"
Post a Comment